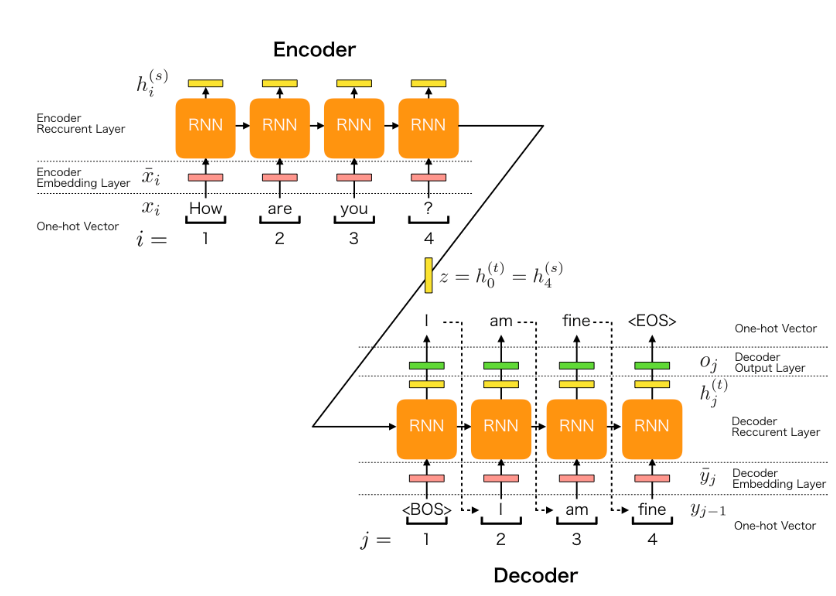
Encoder-Decoder architecture
Encoder
Reads the entire input sequence and compresses it into a fixed-size context vector (final hidden state, often called "encoding" or "embedding") (Many-to-One)
Analyses input, producing final memory vector output. Can be done with an RNN, with the final memory state consisting of the encoding vector.
Decoder
Initializes its hidden state with the context vector from the encoder and generates the output sequence step-by-step. (Effectively One-to-Many, conditioned on the context)
Analyses the produced encoding vector, and produce a sequence of some sort as output. Can be done with an RNN, where the first memory state consists of the encoding vector.