ELMo
Embeddings for Language Model - Deep Contextualised Word Representations
ELMo expects inputs of entire sentences, and will produce embeddings for all words in the sentence separately.
ELMo decomposes words inputs into characters, which will then be represented as one-hot vectors and fed as inputs. This handles OOV words naturally, with lower input dimensionality compared to word one-hot vectors.
- Input of words as a list of characters into a character-level network
- To get an embedding of a word, input the whole sentence for context, then take only the vector which corresponds to the word
- Use multiple layers of RNNs on word-level
- Use highway layers for transition in the middle
- Train whole network for task of predicting next word in sentence
- Extract embedding layer for feature representation
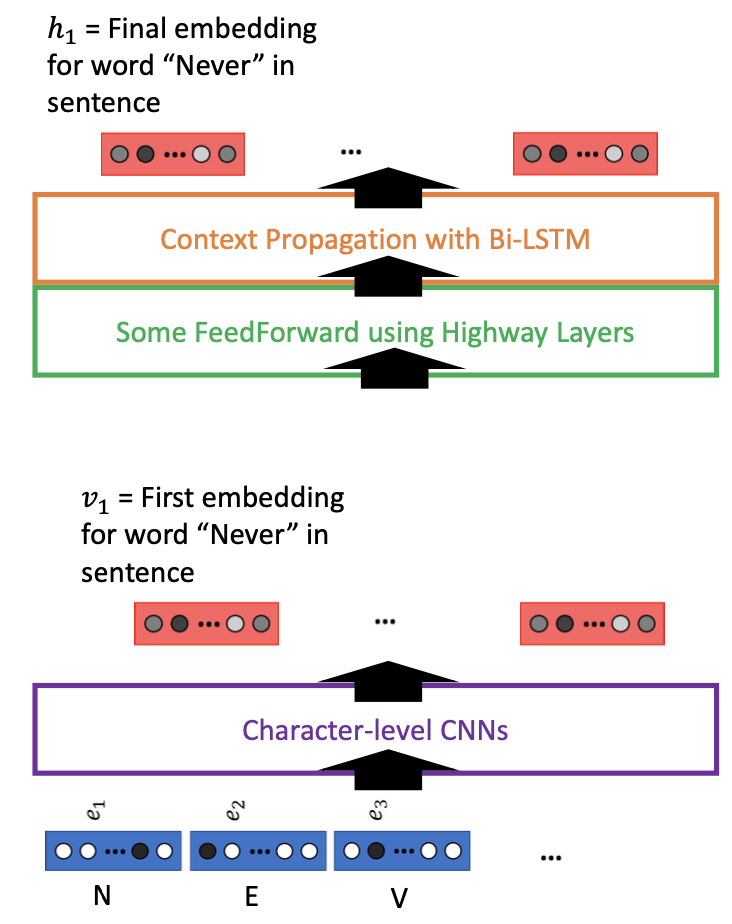
Architecture
Character-level vectors go through 1D Convolutional Neural Networks with different kernel sizes - the original model used kernels of size 1, 2, 3, 4, 5, 6, 7 with 32, 32, 64, 128, 256, 512, 1024 channels respectively.
- Each CNN using different kernel sizes looks at: characters, then bigrams, trigrams...
- Produces an output sequence of feature vectors
The outputs from each layer are max-pooled and concatenated. This final concatenated vector of size 2048 can be used as a first word embedding, regarded as a character-level context extraction process, but does not benefit from context yet.
- Max-pooling looks at the entire sequence of feature vectors produced by one CNN and finds the maximum value across the entire sequence length - this is the single most salient feature detected by the CNN filter anywhere within the word.
- Concatenation takes the fixed-size vectors produced by each of the max-pooled CNN outputs and stacks them end-to-end into one larger vector. This aggregates the information captured with a comprehensive initial representation of the word based on its character composition, capturing patterns of various lengths.
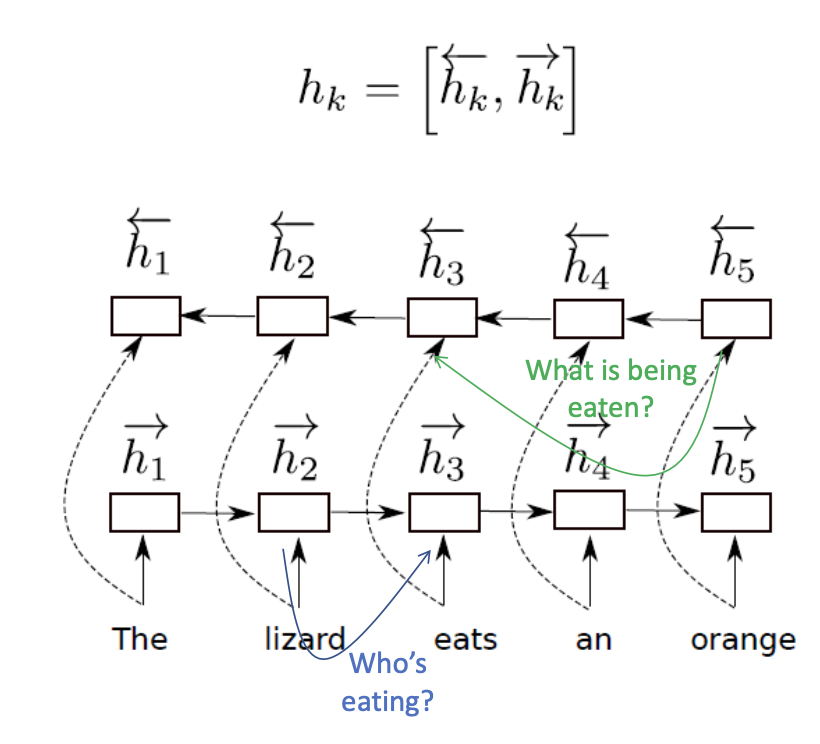
Now, we want a layer to combine and transfer context from words to each other. We can use bidirectional LSTMs with two hidden states, going in two opposite directions.
with
We also add some Feedforward layers in the middle to allow for smoother transition from character-level CNNs output to Bi-LSTM input. This can be done with a succession of Linear layers, or a variation called a Highway Layer.