Convolution
Mathematical operation: applies a small matrix called a convolution kernel or filter
over a given image , element-wise multiplying each overlapping set of values with the kernel and then summing the results
Each output represents the sum of the product of the input and the pixel.
Used in Computer vision. For instance
Types of kernels
Choosing the right kernel size for convolution:
- Larger kernel preferred for information distributed more globally (zoomed-in)
- Smaller kernel preferred for information distributed more locally (zoomed-out)
Conv2d
def convolution_batch_torch_conv2d(images, kernel, stride = 1, padding = 0):
# Convert kernel to PyTorch tensor, if needed
kernel = torch.from_numpy(kernel)
kernel = kernel.view(1, 1, kernel.shape[0], kernel.shape[1])
kernel = kernel.float()
# Flip the kernel (optional)
kernel = torch.flip(torch.flip(kernel, [2]), [3])
# Create a convolutional layer
conv = torch.nn.Conv2d(in_channels = images.shape[1], \
out_channels = 1, \
kernel_size = kernel.shape[2:], \
stride = stride, \
padding = padding)
# Assign the kernel to the layer
conv.weight = torch.nn.Parameter(kernel)
conv.bias = torch.nn.Parameter(torch.tensor([0.0]))
# Perform convolution
output = conv(images)
return output
Formatted as a 4D tensor of size
the number of samples/images in batch of data , , the number of channels in images of batch (e.g. greyscale = 1, RGB = 3), , the height for images batch of data , , the width for images batch of data .
For RGB (not grayscale images), follow [[#Higher dimension convolution]].
Chaining convolutions
nn.Conv2d(1, 32, kernel_size = 3, stride = 1, padding = 1)
The first two integer values correspond to the number of channels of input images X and the number of channels in kernel.
The convolution layer below then expects grayscale images X with only one channel and will produce images Y with 32 channels.
This image
These filters are initialised (see Constant initialisation), and the Convolutional Neural Networks will learn the best filters on its own.
nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
By stacking multiple convolutional layers, the network can learn hierarchical features, where lower layers detect simple patterns and higher layers detect more complex structures.
Padding
Convolution produces a new image
Hence, we have to pad the image - add extra pixels on the outer part of the original image. This artificially increases the size of the original mimage
Valid padding
By default, with no padding applied to the input data. Convolution is thus only performed on the valid parts of input, with the output size being smaller than the input size.
Same padding
We add a padding size
When using a padding with size
Thus, the padding size
Interpolation padding
Similar to same padding, but we use the value of the closest pixel instead of zeros. This supports zooming into the original image, which means we can resize the image and then apply interpolation techniques before convolution such that the output
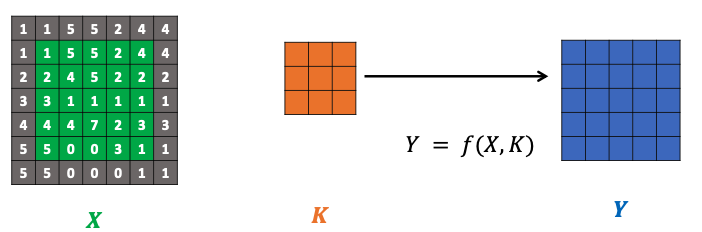
image = np.pad(image, ((padding, padding), (padding, padding)), 'constant')
Stride
Controls the movement or step size of the convolution filter as it slides over the input image
Larger stride results in a smaller output feature map, and the converse is true.
Stride can help reduce the spatial dimensions of the feature map, reducing the number of parameters and computation.
A stride of 2 means we are sliding to every other pixel.
Dilation
Spacing between values of original image multiplying the kernel. By default
For
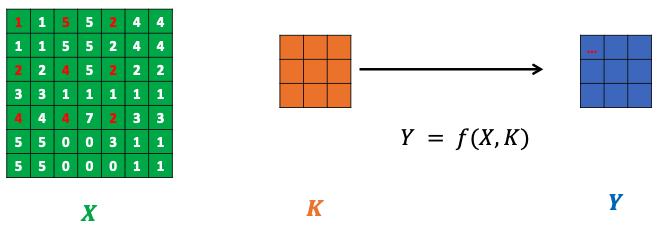
Convolution formula
- Given a 3D tensor
of size , of height , weight and number of channels - A convolution kernel
of size - A padding of size
, a stride of size , a dilation of size
The resulting image
- & Floor function used in case division result has to be an integer
Higher dimension convolution
With a 2D kernel:
For pixels
This preserves the original number of channels of original image
For a kernel as a tensor with its own number of channels
For pixels
This produces a new image