Computer vision
We encode each element in a greyscale or RGB matrix (which correspond to a pixel) but individual pixels are impossible to extract information from.
Pixels however have certain properties
This means that we cannot use linear operations (which we have been using, see Linear regression) as:
- The image would be flattened into a 1D vector, losing the structure and spatial information of the image. They do not take into account the spatial dependence
- The pixels would be processed independently with coefficients applied to each pixel separately as it assumes each pixel is independent of the others, msising important spatial relationships between pixels
This is solved by using Convolution, resulting in a new image
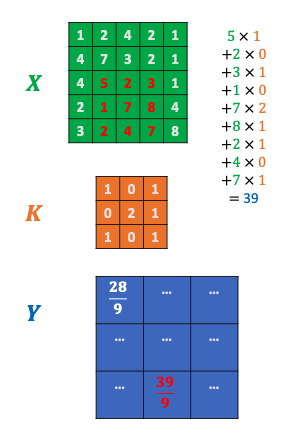
Using convolution
- 2D matrix
of size with pixel values - Convolution kernel
of size with values , which produces an image of size . is often odd sized
- & Weighted average of a pixel and its neighbouring pixels.
# Our convolution function
def convolution(image, kernel):
# Flip the kernel (optional)
kernel = np.flipud(np.fliplr(kernel))
# Get the dimensions of the image and kernel
image_rows, image_cols = image.shape
kernel_rows, kernel_cols = kernel.shape
# Convolve using Numpy
output = correlate(image, kernel, mode = 'valid')
# Note that this is equivalent to this
"""
# Loop through the image, applying the convolution
output = np.zeros_like(image)
for x in range(image_rows - kernel_rows + 1):
for y in range(image_cols - kernel_cols + 1):
output[x, y] = (kernel * image[x:x+kernel_rows, y:y+kernel_cols]).sum()
"""
return output
# Display image in matplotlib
plt.imshow(image_conv1, cmap = 'gray')
plt.show()
Flipping the kernel
- ? Why is the convolution filter flipped in CNN?
Answer here, will revisit someday